Tenemos mucho que compartir sobre este tema. Así que si quieres aprender al respecto mantente atento.
Primero debes saber que divideremos la información en dos partes:
En este artículo abordaremos los conceptos básicos de GraphQL, además diseñaremos una API sencilla desde cero y la desplegaremos con el servicio AWS AppSync y serverless framework.
En la siguiente parte crearemos una aplicación del lado del cliente para consumir la API. Utilizaremos el framework Amplify+ReactJS y además daremos más funcionalidades a nuestra API mediante el uso de suscripciones para un caso de uso en tiempo real.
¿Qué es GraphQL?
Graphql es un lenguaje de consulta de datos para API, la idea fundamental es hacer que la API esté disponible a través de un único endpoint, en lugar de acceder a varios como se hace actualmente con REST.
Entre las ventajas de GraphQL podemos nombrar las siguientes:
-
El cliente puede especificar exactamente la estructura de los datos que serán servidos.
-
Carga de datos eficiente, mejorando en gran medida el uso del ancho de banda.
-
Estilo declarativo y auto-documentativo gracias a los esquemas fuertemente tipados.
Esquemas
Los esquemas determinan la capacidad de la API y definen tres operaciones fundamentales: query, mutation, subscription. También incluye los parámetros de entrada y las posibles respuestas.
Solucionadores
Los solucionadores implementan la API y describen el comportamiento del servidor. Básicamente son funciones que se encargan de obtener datos para cada campo definido en el esquema.
AWS Appsync+Serverless Framework
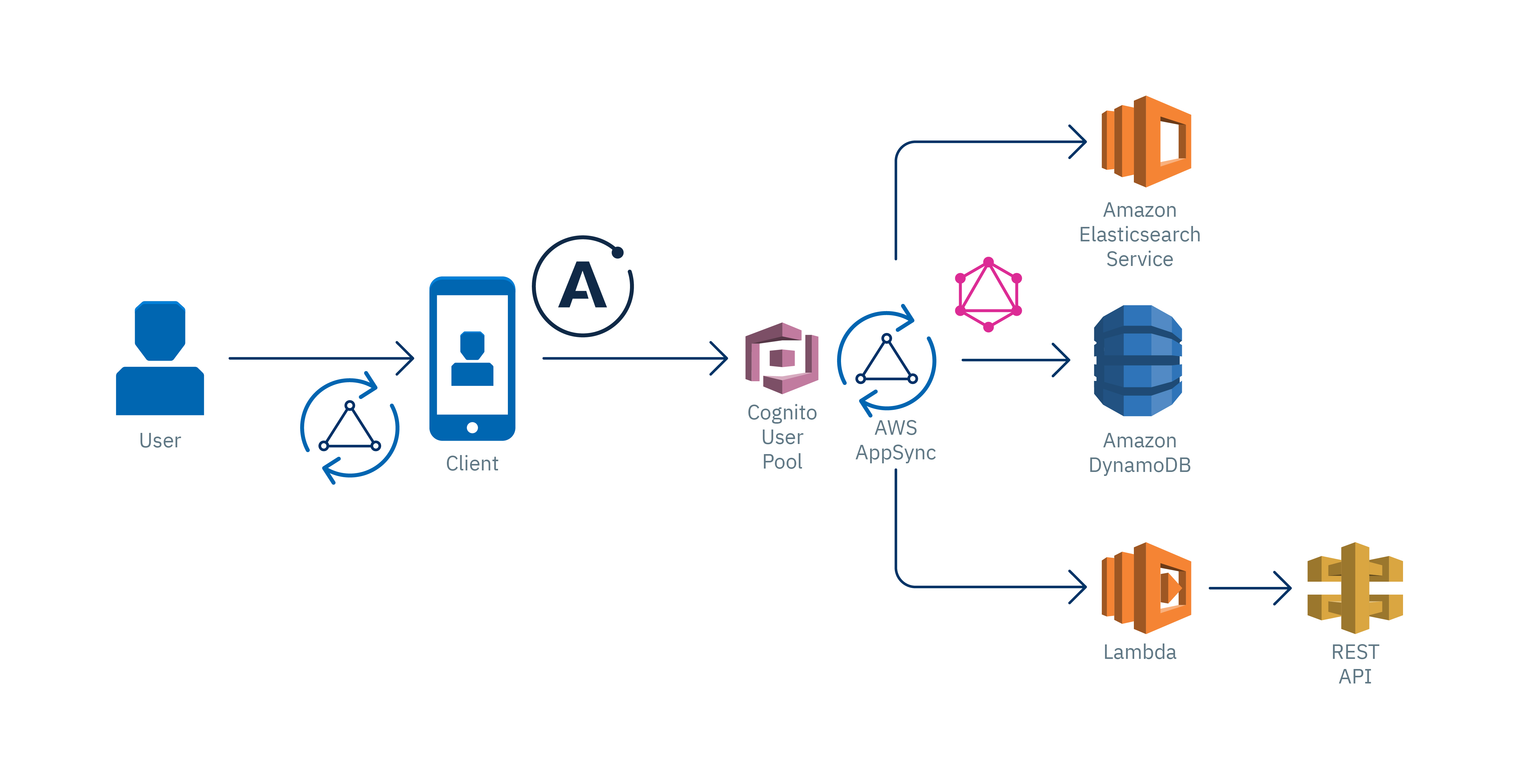
AppSync es un servicio serverless gestionado por AWS, es una capa de GraphQL que nos permitirá desarrollar nuestra API de manera ágil. Es importante conocer los componentes básicos de AppSync:
-
Esquema: como lo mencionamos anteriormente aquí definiremos los tipos y operaciones básicas para recuperar y guardar los datos.
-
Solucionadores: define las plantillas de mapeo de solicitud y respuesta para cada campo definido en el esquema. Están escritas en VTL y se encargan de interpretar las respuestas de las fuentes de datos y también analizan las solicitudes.
-
Fuentes de datos: integración con los servicios de AWS: DynamoDB, Lambda, RDS y ElasticSearch.
-
Autenticación: podemos autenticar la API con API_KEY, IAM o Cognito User Pools
Como podemos ver AppSync proporciona algunas herramientas para construir una API GraphQL de manera fluida, se puede seguir una serie de pasos desde la consola de AWS AppSync y en cuestión de minutos podemos tener algo funcional. Sin embargo preferimos hacerlo de una forma más cercana a la realidad de aplicaciones modernas en producción.
Aquí entra en juego serverless framework una tecnología robusta para definir la infraestructura como código orientado a aplicaciones serverless para diferentes proveedores cloud. En Kushki creemos que hoy en día es crucial tener una infraestructura serverless versionada y automatizada, veremos que es una forma práctica y eficiente de implementar nuestra API. Serverless tiene varias opciones para desplegar AppSync en la nube.
Sin más empecemos a poner en práctica todos estos conceptos mediante una sencilla aplicación.
La aplicación: To do List
En esta primera parte del artículo crearemos la API GraphQL de un CRUD To do List. Usaremos DynamoDB para la base de datos.
Requisitos:
Empecemos instalando serverless y un plugin para Appsync:
npm install -g serverless serverless-appsync-plugin
En el directorio principal del proyecto ejecutamos el siguiente comando para crear una plantilla con las configuraciones necesarias para crear una aplicación serverless en AWS.
serverless create --template aws-nodejs
Nota: agrega serverless-appsync-plugin en la sección plugins del archivo serverless.yml:
Primero definimos parte de nuestra infraestructura. Para esto, crearemos una tabla todos en DynamoDB en serverless.yml. Por el momento no nos preocuparemos sobre las diferentes configuraciones, con el siguiente fragmento de código bastará:
resources:
Resources:
todos:
Type: "AWS::DynamoDB::Table"
Properties:
TableName: todos
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
BillingMode: PAY_PER_REQUEST
Define un esquema GraphQL
En la raíz crea un archivo schema.graphql. Aquí es donde definimos nuestro esquema y los tipos de datos. Por el momento definiremos las operaciones query y mutation. GraphQL maneja su propia sintaxis llamada SDL, aquí puedes revisar mas sobre este tema.
schema {
query: Query
mutation: Mutation
}
type Query {
listToDos: [ToDo]
getToDoById(id: ID!): ToDo
}
type Mutation {
createToDo(input: CreateToDoInput!): ToDo
updateToDo(input: UpdateToDoInput!): ToDo
deleteToDo(id: ID!): Boolean
}
type ToDo {
id: ID!
name: String
title: String!
description: String
completed: Boolean!
}
input CreateToDoInput {
id: ID!
name: String!
title: String!
description: String!
completed: Boolean!
}
input UpdateToDoInput {
name: String!
title: String!
description: String!
completed: Boolean!
}
Recordemos que para cada campo definido se requiere implementar un solucionador. En este caso los solucionadores son consultas a DynamoDB escritas en VTL. Existen algunas funciones de utilidad que hacen más fácil su implementación, para más información de plantillas de mapeo de solucionadores puedes visitar este link.
Solucionador createToDo:
Creamos un directorio mapping-templates en la raíz del proyecto donde alojamos los solucionadores de petición y respuesta por cada campo creado en el esquema.
Petición: crear archivo createToDo-request.vtl e insertar el siguiente código:
{
"version" : "2017-02-28",
"operation" : "PutItem",
"key" : {
"id" : $util.dynamodb.toDynamoDBJson($context.arguments.input.id)
},
"attributeValues" : {
"name" : $util.dynamodb.toDynamoDBJson($context.arguments.input.name),
"title" : $util.dynamodb.toDynamoDBJson($context.arguments.input.title),
"description" : $util.dynamodb.toDynamoDBJson($context.arguments.input.description),
"completed" : $util.dynamodb.toDynamoDBJson($context.arguments.input.completed)
}
}
Con la variable $context.argument podemos acceder a los parámetros de entrada que hemos definido en nuestro esquema.
Respuesta: crear archivo createToDo-response.vtl e insertar el siguiente código:
$utils.toJson($context.result)
No te preocupes en como se obtienen los datos desde DynamoDB, AppSync realiza la conexión con las fuentes de datos, los devuelve en la variable $context.result y $utils.toJson lo presenta en un formato entendible para GraphQL. Si deseas procesar estos datos en el solucionador lo puedes hacer con VTL.
Solucionador updateToDo:
Petición: crear archivo updateToDo-request.vtl e insertar el siguiente código, en este caso usaremos una operación de UpdateItem de DynamoDB:
{
"version" : "2017-02-28",
"operation" : "UpdateItem",
"key" : {
"id" : $util.dynamodb.toDynamoDBJson($context.arguments.input.id)
},
"update" : {
"expression" : "SET name = :name, title = :title, description = :description, completed = :completed",
"expressionValues": {
":author" : $util.dynamodb.toDynamoDBJson($context.arguments.input.name),
":title" : $util.dynamodb.toDynamoDBJson($context.arguments.input.title),
":content" : $util.dynamodb.toDynamoDBJson($context.arguments.input.description),
":url" : $util.dynamodb.toDynamoDBJson($context.arguments.input.completed)
}
}
}
Respuesta: crear archivo createToDo-response.vtl e insertar el siguiente código:
$utils.toJson($context.result)
Solucionador getToDoById:
Petición: crear archivo getToDoById-request.vtl e insertar el siguiente código:
{
"version" : "2017-02-28",
"operation" : "GetItem",
"key" : {
"id" : $util.dynamodb.toDynamoDBJson($context.args.id)
}
}
Respuesta: crear archivo getToDoById-response.vtl e insertar el siguiente código:
$utils.toJson($context.result)
Definimos nuestra infraestructura de AppSync y el archivo servereless.yml en donde definimos los solucionadores (mappingTemplates), esquema (schema), fuente de datos(dataSources) y el tipo de autenticación(authenticationType), debería tener la siguiente estructura, :
service:
name: appsync-todo-app-backend
plugins:
- serverless-appsync-plugin
custom:
appSync:
name: todo-app
authenticationType: API_KEY
mappingTemplates:
- dataSource: todos
type: Mutation
field: createToDo
request: "createToDo-request.vtl"
response: "createToDo-response.vtl"
- dataSource: todos
type: Mutation
field: updateToDo
request: "updateToDo-request.vtl"
response: "updateToDo-response.vtl"
- dataSource: todos
type: Query
field: getToDoById
request: "getToDoById-request.vtl"
response: "getToDoById-response.vtl"
schema: # defaults schema.graphql
dataSources:
- type: AMAZON_DYNAMODB
name: todos
description: 'Todos table'
config:
tableName: todos
provider:
name: aws
runtime: nodejs12.x
resources:
Resources:
todos:
Type: "AWS::DynamoDB::Table"
Properties:
TableName: todos
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
BillingMode: PAY_PER_REQUEST
Finalmente ejecutamos el siguiente comando para desplegar nuestra API en la nube de AWS:
serverless deploy
Probando nuestra API GrapQL:
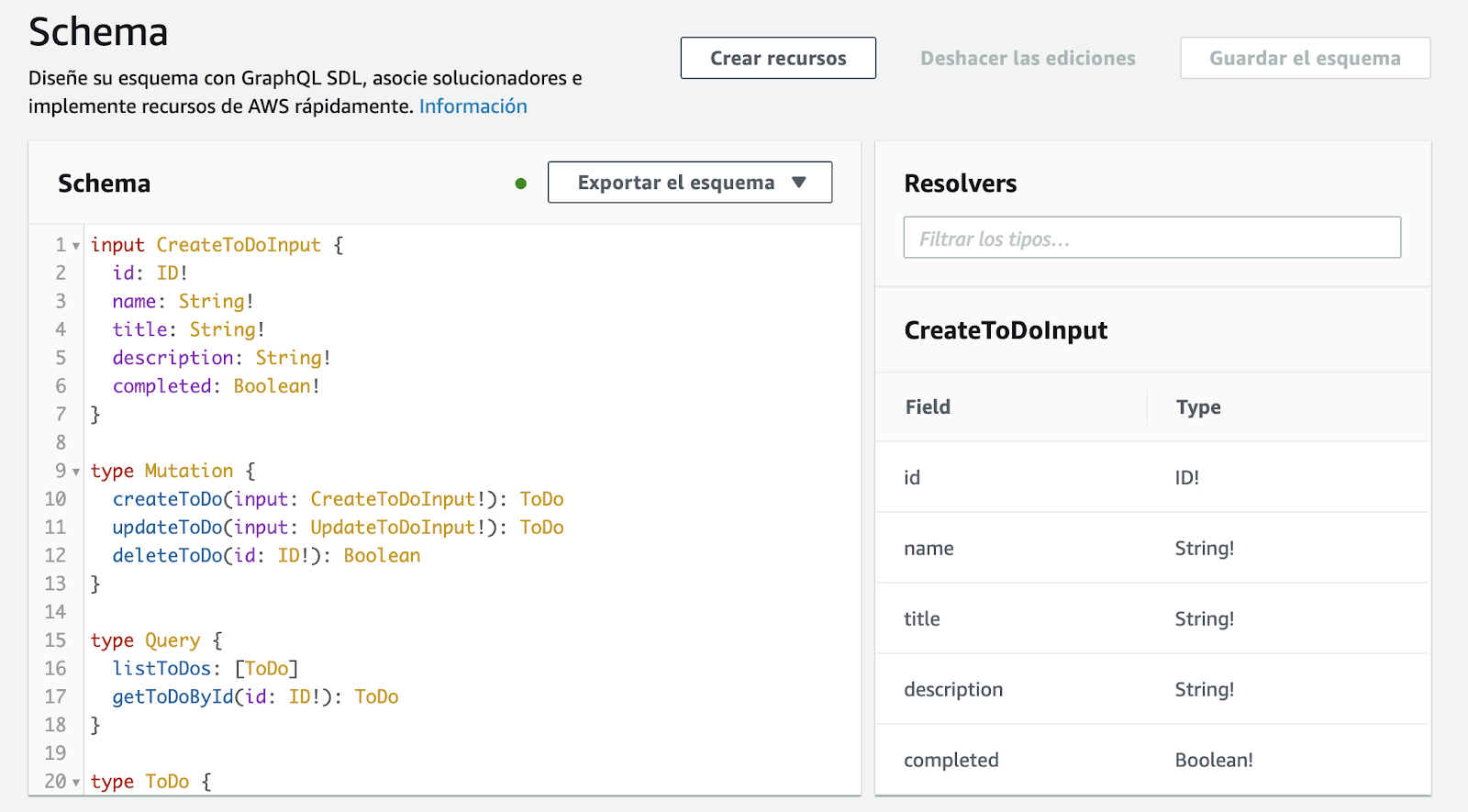
Si abrimos la consola de AWS AppSync veremos el esquema, los solucionadores, la autenticación y la fuente de datos que hemos definido.
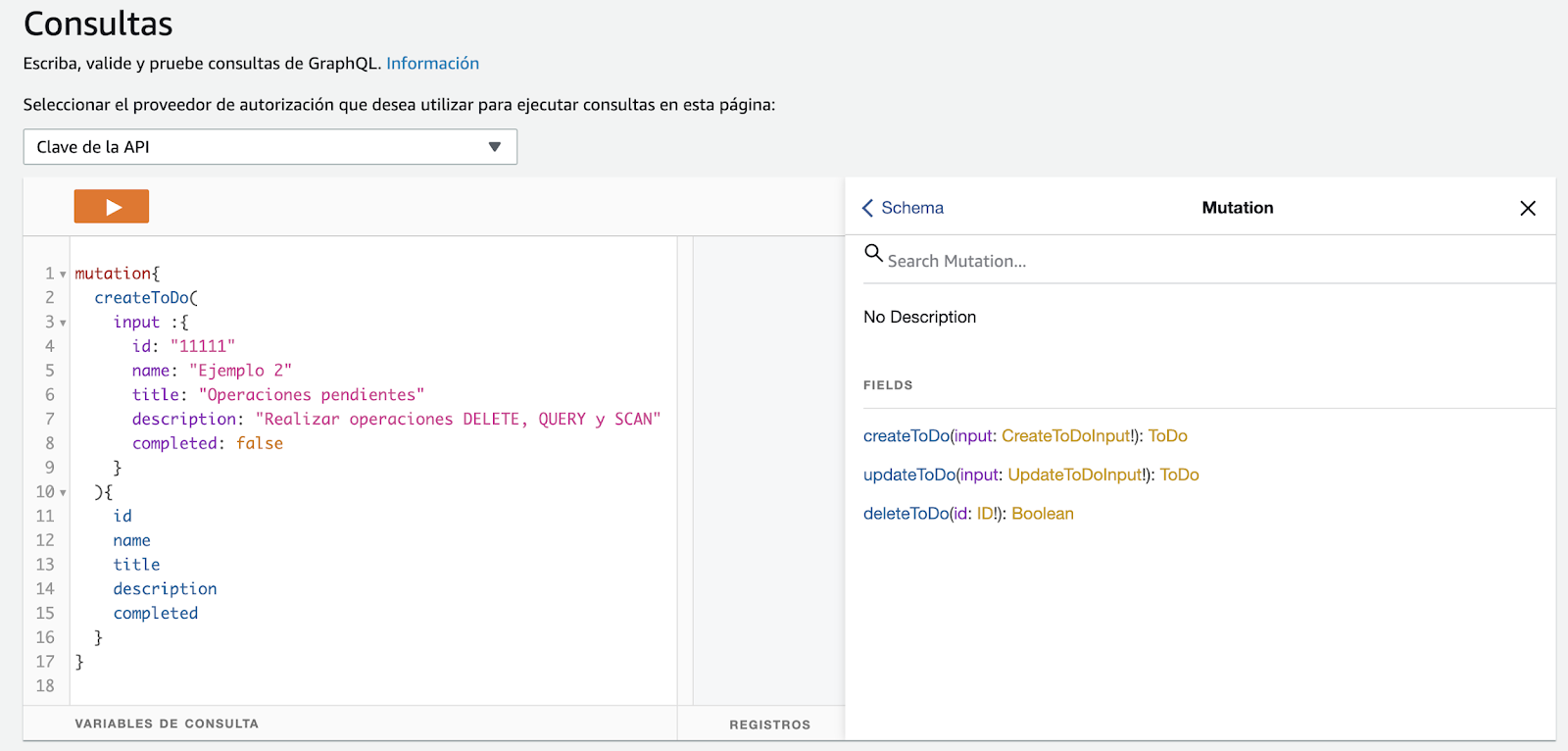
Por otro lado también tenemos un cliente GraphQL con el cual podemos realizar pruebas de nuestra API. En la siguiente figura podemos observar la documentación de la API de acuerdo a los esquemas definidos.
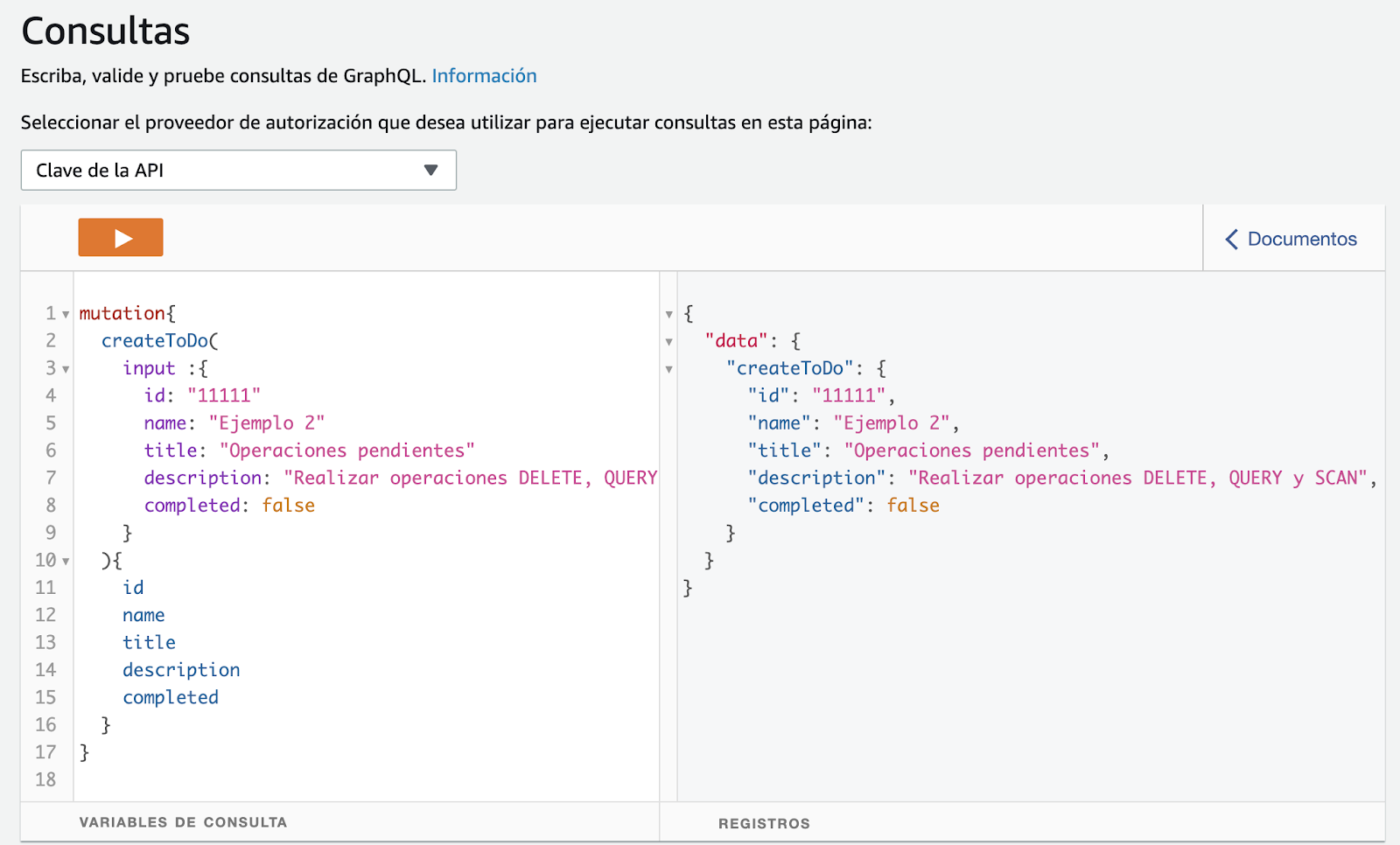
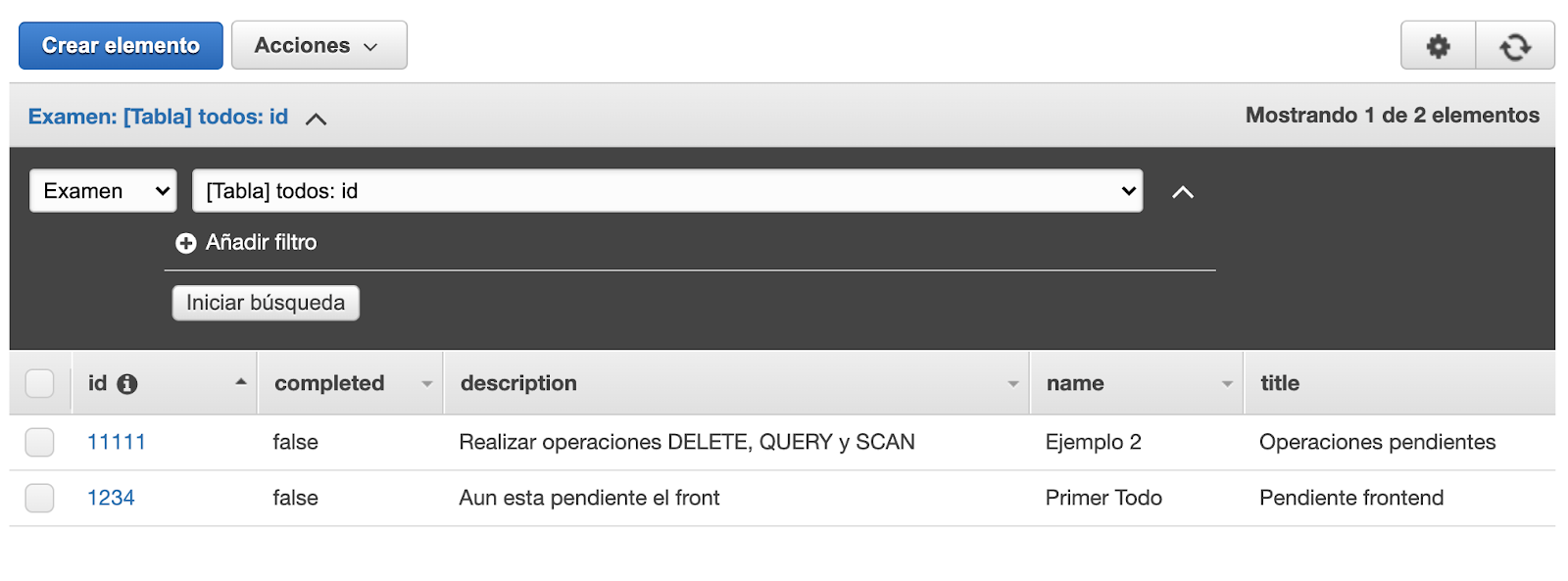
Al ejecutar la operación de mutación createToDo se crea un registro en DynamoDB y devuelve el objeto creado según los campos definidos.
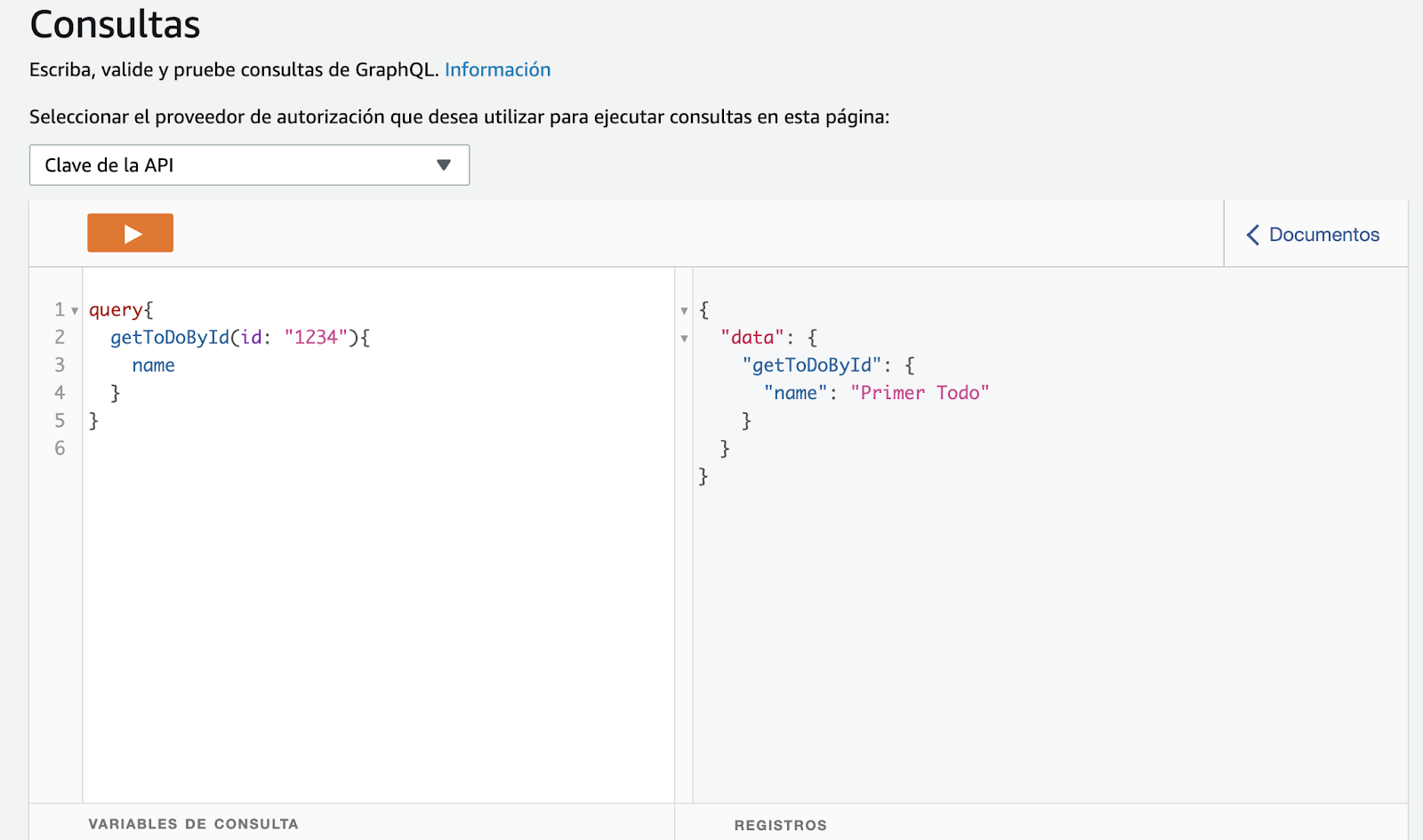
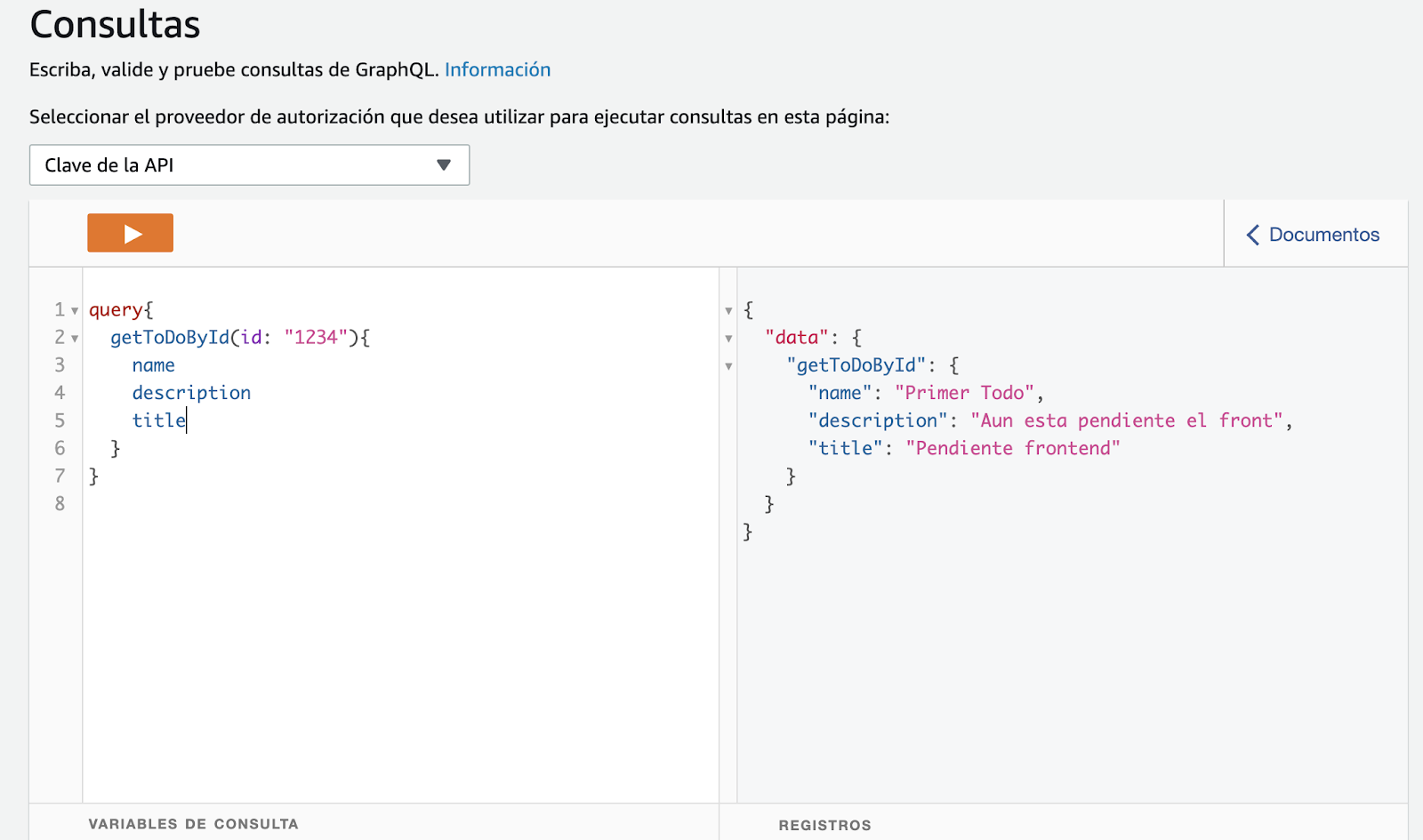
Para recuperar los datos de un ToDo ejecutamos la operación query de getToDoById, podemos solicitar solo el campo name o los que sean necesarios.
Ahí lo tuviste:
En este artículo abordamos los conceptos básicos de GraphQL, además diseñamos una API sencilla desde cero y la desplegamos con el servicio AWS AppSync y serverless framework.
Recuerda que aún queda una siguiente parte, en la que crearemos una aplicación del lado del cliente para consumir la API. Utilizaremos el framework Amplify+ReactJS y además daremos más funcionalidades a nuestra API mediante el uso de suscripciones para un caso de uso en tiempo real.
Te esperamos en la segunda parte de este artículo.












