Deployments tipo canary
Hoy te contaremos sobre una técnica donde el código desplegado a producción no se cambia al instante por el código anterior, sino en un lapso de tiempo y bajo un ambiente controlado, para permitirte dormir tranquilo por la noche.
Es muy común pensar que la única forma en que las empresas de tecnología despliegan su código en producción sea durante horas no laborables y abriendo ventanas de mantenimiento para sus clientes.
Esta es una práctica antigua adoptada por empresas grandes que, de cierta manera, funciona, pero ¿a qué costo? Al costo de tener un equipo dedicado para esos despliegues, horas extras, horarios nocturnos y significativa carga para los empleados y las empresas.
Además, al introducir nuevas funcionalidades en producción, por más pruebas que se hayan realizado (pruebas punta a punta y pruebas unitarias), siempre existe el riesgo del factor humano, pues nadie es perfecto y algo puede fallar. Por esa razón, se opta por deployar en horas no laborables. Ante estos abrumadores problemas, que muchas veces separan al desarrollador de software de su preciado sueño, llegan los deployments de tipo canary.
Los deployments tipo canary son una técnica donde el código desplegado a producción no se cambia al instante por el código anterior, sino que en un lapso de tiempo y bajo un ambiente controlado se monitorea errores, estadística y demás para reemplazar el código en su totalidad o dar rollback. Eso mi querido lector, es lo que te vengo a contar en este artículo.
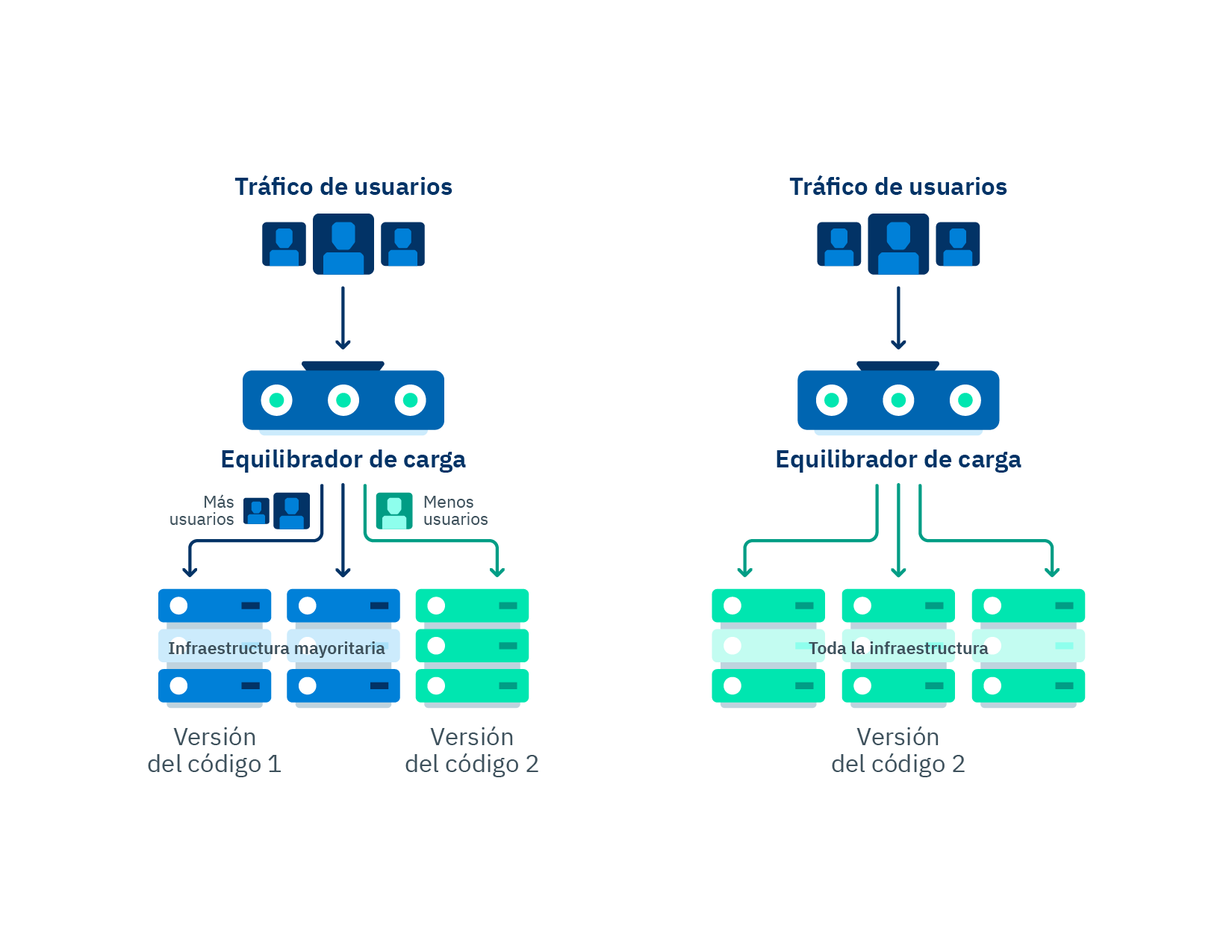
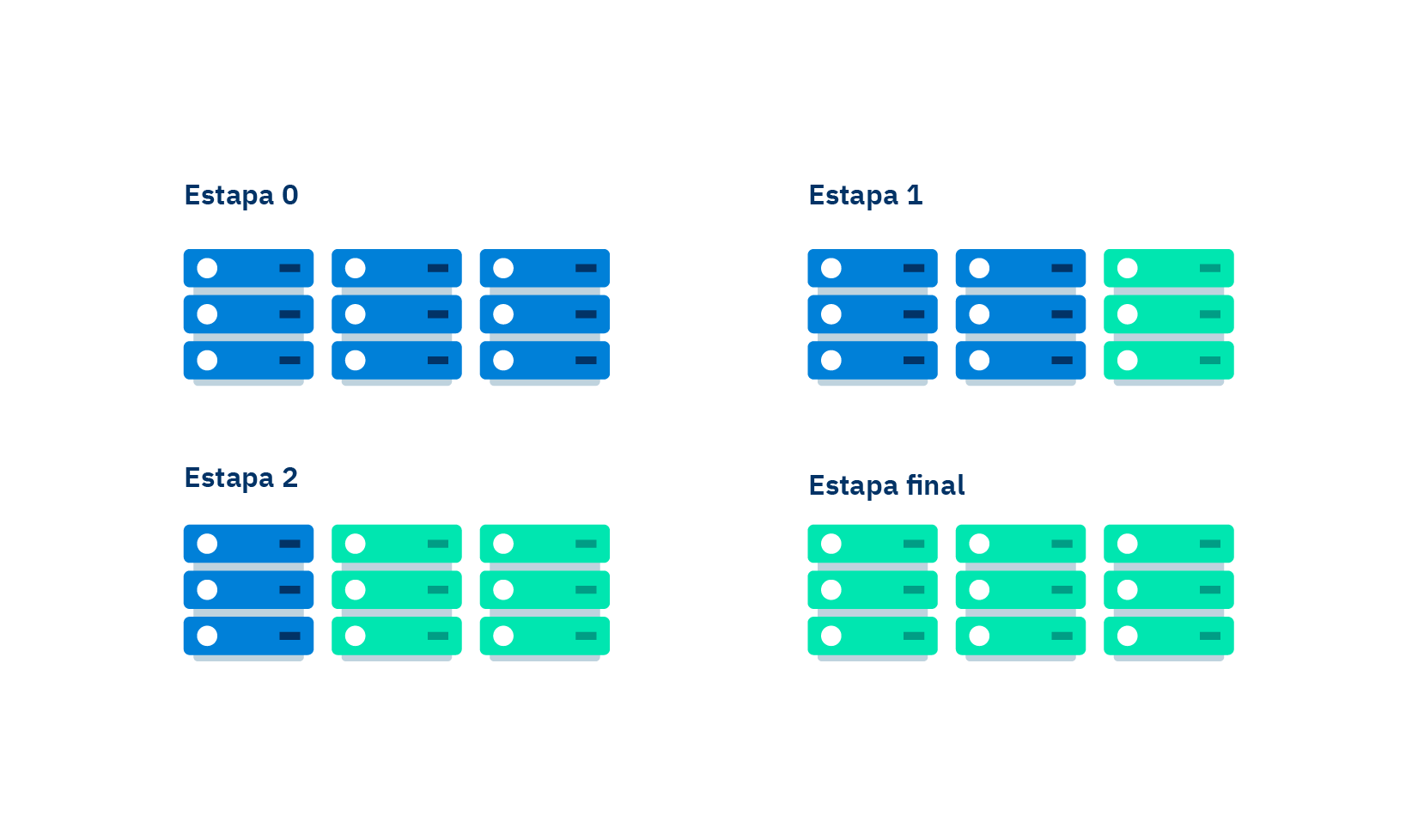
Diagrama del antes, durante y después de un deploy tipo canary.
Los deployments tipo canary nacen justamente por la necesidad y la obsesión del desarrollador de software de lograr controlar hasta el último detalle de un deploy (despliegue) a producción. A nadie le gusta meter bugs en producción, pero es algo con lo que todos los que hemos programado hemos tenido que lidiar y sabemos que no desaparecerá, pues es parte de la imperfección del ser humano. Sin embargo, lo que sí podemos hacer es reducir esos bugs al mínimo y que, si aparecen, sea solo en componentes y funcionalidades no críticas de un producto o servicio, para minimizarlos tanto en número como en impacto hacia el producto.
El deploy tipo canary consiste en introducir una nueva versión del código desarrollado y hacerlo disponible a una pequeña parte de los usuarios, e ir incrementando el número de usuarios con acceso a éste en un lapso de tiempo determinado. Así por ejemplo se puede lanzar el tipo 10percentEveryMinute, lo que significa que al primer minuto de deployado el código en producción sólo el 10% de los usuarios lo estará usando, mientras que el otro 90% restante seguirá accediendo al código antiguo. El porcentaje de uso del nuevo código se irá incrementando progresivamente hasta completar el despliegue total.
El despliegue paulatino puede venir acompañado de alarmas de monitoreo automatizadas que, si detectan que el nivel de errores en el código que está siendo puesto a prueba es mayor al threshold (umbral) permitido, se hace un rollback automático. Entendiendo como rollback a la funcionalidad de abortar el nuevo despliegue a producción, usado, generalmente, porque se encontraron errores en el código nuevo.
Igualmente, puedes complementar el monitoreo de las alarmas con funciones que corran antes y después de empezar el despliegue, esto con el fin de asegurar que el código a probar no tenga ningún problema. La idea es, poner a correr el sistema de pruebas con el código antiguo que sabemos que funciona, en una primera etapa, para luego repetir esta prueba con el código nuevo. Con esto se evita que el despliegue aleatorio, por mala suerte, haya hecho invisible algún posible bug durante el deploy por simple estadística.
De esta manera, los deploy tipo canary te permiten:
-
Realizar despliegues a producción en un ambiente controlado.
-
Mayor facilidad para hacer rollback.
-
Versionar el código en producción.
-
Reducir significativamente los bugs.
Como podemos ver, el deploy tipo canary tiene bastantes bondades bien vistas por desarrolladores al momento de lanzar código a producción, pero también quiero poner en perspectiva que si la estadística está mal leída, puede llegar a causar que se aborten deploys por resultados llenos de falsos positivos de errores que, en realidad, no ocurrieron. Pues, durante el deploy pueden presentarse problemas de proveedores o de terceros con los cuáles se está integrado, y al tener la medición de errores de forma automatizada, el deploy quedará cancelado automáticamente, tomando los problemas de estos terceros como nuestros.
Esto refuerza la necesidad de establecer más mecanismos de control, que aunque alargarán el proceso de salida a producción, reducirán en gran medida el margen de error y evitaremos caer en falsos positivos.
A continuación podrás ver un ejemplo práctico del deploy tipo canary utilizando el framework Serverless.
Podrás configurar el deploy tipo canary de una manera muy simple, en una estructura de un proyecto serverless, con las siguientes líneas de código:
El deploy tipo canary queda configurado de una manera muy simple en una estructura de un proyecto serverless con las siguientes líneas de código:
Paso 1: Instala la versión del plugin en el archivo package.json
"serverless-plugin-canary-deployments": "0.4.8"
Paso 2: Referencia el plugin en la sección 'plugins' del archivo serverless.yml
plugins:
- serverless-plugin-canary-deployments
Paso 3: Configura las opciones del canary a utilizar. En este ejemplo, especificaremos dos alarmas, los ambientes a aplicar el deploy tipo canary y el tipo.
deploymentSettings:
stages:
- ci
- qa
- stg
- uat
- primary
type: 10percentEvery1Minute
alias: Live
alarms:
- ErrorChargesGatewayAlarm
- ErrorChargesCountAlarm
Paso 4: Referencia la configuración del canary deploy en la función lambda a aplicar.
functions:
record:
handler: src/handler/RecordHandler.HANDLER
deploymentSettings: ${self:custom.deploymentSettings}
Y ¡listo!
Hemos analizado gran parte de los pros y contras que podemos encontrar en un deploy tipo canary, desde el concepto hasta un ejemplo práctico de cómo hacerlo funcional. Sin dudas, esta práctica se está volviendo una tendencia cada vez más utilizada en el mundo del desarrollo de software ya que minimiza errores en componentes críticos de un sistema de software, permitiendo a los desarrolladores dormir tranquilos por las noches.







