Canary-type implementations
Today, you will learn about a technique where code deployed to production will not be replaced instantly by the previous code, but within a time frame and under a controlled environment, so you can sleep peacefully at night.
It is a widespread idea that the only way technology companies can deploy their code to production is at non-working hours and opening maintenance windows for their clients.
This is an old practice adopted by big companies, and it works to some extent, but at what cost? At the cost of having a dedicated team for those deployments, extra hours, night schedules and a significant workload for employees and companies.
In addition, when introducing new features to production, even after full tests have been performed (point-to-point testing and unit testing), there is always the risk of the human factor, because nobody is perfect and something can fail. For this reason, companies prefer to deploy code at non-working hours. To solve these overwhelming problems, that often deprive software developers from their precious sleep, canary deployments were invented.
A canary deployment is a technique where code deployed to production is not replaced by the previous code instantly, but within a time frame and under a controlled environment; errors, statistics and other features are monitored to replace the complete code or to roll back to the previous one. This, my dear reader, is what I will tell you in this article.
Flow chart of a canary deployment, before, during and after deployment.
Canary deployments were developed precisely to satisfy the need and the obsession of software developers to achieve control over even the smallest detail of a deployment to production. Nobody likes inserting bugs in production, but they are something we all programmers have had to deal with, and we know that they will not disappear because they come from the imperfection of human nature. Nevertheless, we can reduce those bugs to the minimum and, if they occur, they can be limited to just some components and non-critical features of a product or a service. We can minimize them in both number and impact to the product.
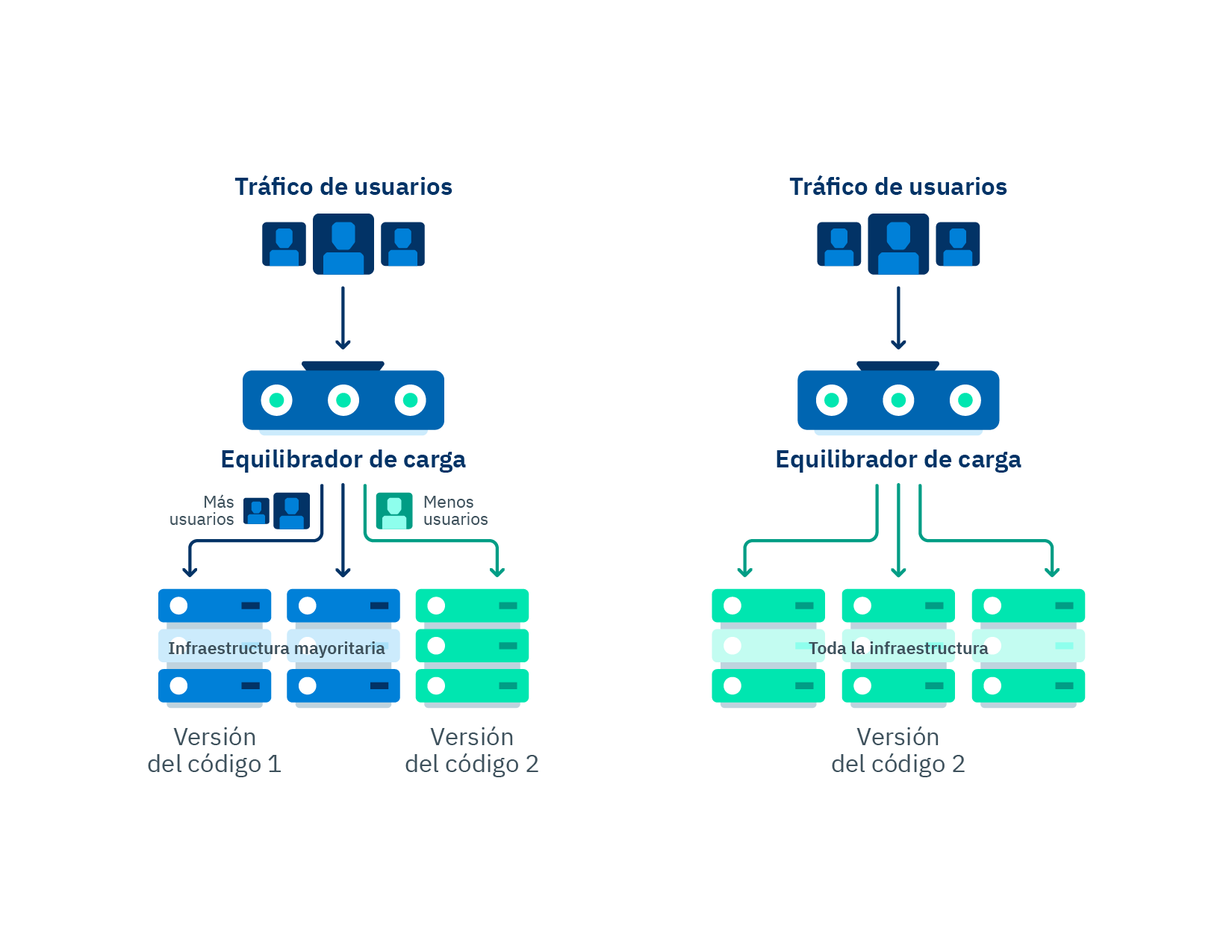
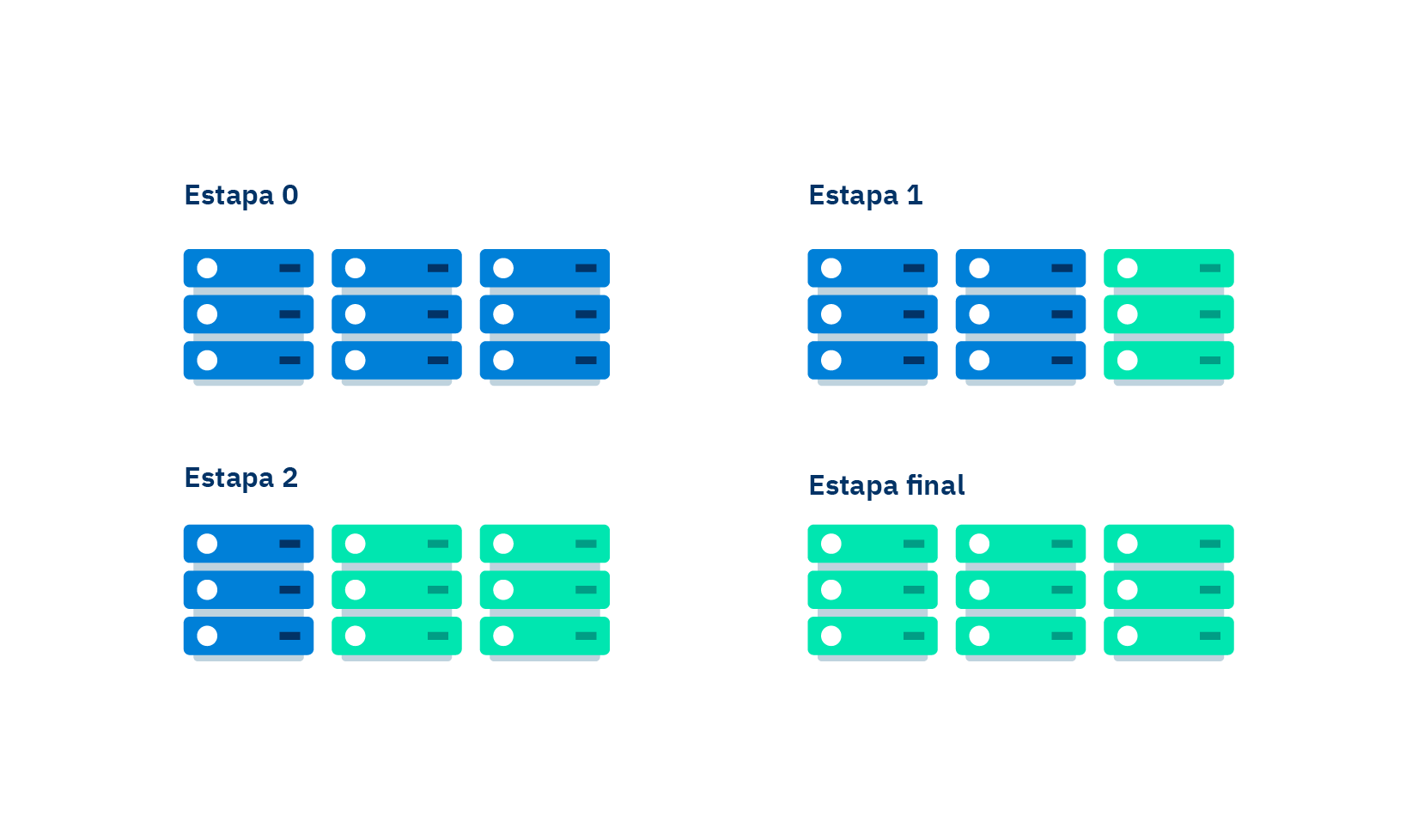
Canary deployments introduce a new version of a developed code and release it for a small part of the users, gradually increasing the number of users with access to it within a specific time frame. For example, you can launch a 10percentEveryMinute deployment, which means that at the first minute of deploying the code to production only 10% of the users will be using it, while the remaining 90% will continue accessing the old code. The usage percentage of the new code will be gradually increased until total deployment has been achieved.
A gradual deployment may be accompanied by automated monitoring alarms that detect the error level of the code that is being tested, if it is higher than the threshold, an automatic rollback will be performed. A rollback is understood as aborting the new deployment to production, a functionality that is generally used when errors were found in the new code.
Likewise, you can complement alarm monitoring by running functions before and after starting the deployment, in order to ensure that the code being tested does not cause any problems. The idea is running a test system using the old code we know is working in the first stage, and then repeat the test using the new code. This allows us to prevent a random deployment that unluckily has hidden any potential bugs during deployment due to simple statistics.
In this way, canary deployments help us to:
-
Perform deployments to production under a controlled environment.
-
Roll back easily.
-
Version code in production.
-
Reduce bugs significantly.
As we can see, canary deployments have a lot of advantages, well-received by developers when releasing code to production. However, I want to put in perspective that if statistics are poorly read, this might cause aborted deploys due to results full of false positives from errors that actually never occurred. During deployment, some problems caused by integrated suppliers or third parties may occur, and, when error measurement is performed automatically, deployment might be also canceled automatically, taking these third parties problems as if they were ours.
This reinforces the need to establish more control mechanisms. Although they will make the process of release to production longer, they also will reduce the error rate, and we will avoid false positives.
Below you will see a practical example of a canary deployment using Serverless Framework.
You can configure a canary deployment in a very simple way by using the structure of a serverless project with the following lines of code:
A canary deployment is configured in a very simple way by using the structure of a serverless project with the following lines of code:
Step 1: Install the plugin version in the package.json file
js "serverless-plugin-canary-deployments": "0.4.8"
Step 2: Reference the plugin in the 'plugins' section of the serverless.yml file
yaml plugins: - serverless-plugin-canary-deployments
Step 3: Set up the options of the canary deployment you will use. In this example, we will specify two alarms, the environments where the canary deployment will be applied and the type of deployment.
yaml deploymentSettings: stages: - ci - qa - stg - uat - primary type: 10percentEvery1Minute alias: Live alarms: - ErrorChargesGatewayAlarm - ErrorChargesCountAlarm
Step 4: Reference the configuration of the canary deployment in the lambda function to be applied. yaml functions: record: handler: src/handler/RecordHandler.HANDLER${self:custom.deploymentSettings}
And that's it!
We have analyzed much of the pros and cons that we can find in a canary deployment, from the concept to a practical example of how to make it functional. Without a doubt, the use of this technique is becoming an increasing trend in the world of software development, as it minimizes errors in the critical components of a software system, allowing developers to sleep peacefully at night.







